
监督学习 半监督学习 无监督学习 强化学习
先放结论
| 类型 | 数据需求 | 学习方式 | 典型任务 |
|---|---|---|---|
| 监督学习 | 大量带标签数据 | 从输入到输出的映射 | 分类、回归 |
| 半监督学习 | 少量标签+大量无标签数据 | 结合标签与数据分布 | 分类(标签不足场景) |
| 无监督学习 | 完全无标签数据 | 发现数据内在结构 | 聚类、降维 |
| 强化学习 | 无需固定数据集 | 环境交互与奖励反馈 | 序列决策、控制任务 |
- 监督学习(Supervised Learning)
带标签的数据(输入-输出对)进行训练,模型学习输入到输出的映射关系
优点:任务明确,效果通常较好。
缺点:依赖大量高质量标签数据,成本高。
- 半监督学习(Semi-Supervised Learning)
核心特点:结合少量带标签数据和大量无标签数据进行训练。
目标:利用无标签数据提升模型性能,解决标注数据不足的问题。
优点:降低对标签数据的依赖,提升模型泛化能力。
缺点:伪标签可能引入噪声,需谨慎处理。
- 无监督学习(Unsupervised Learning)
核心特点:完全使用无标签数据,模型自行发现数据中的结构或模式。
目标:探索数据内在关系,如聚类、降维或关联分析
优点:无需标注数据,适合探索性分析。
缺点:结果可能难以解释,任务目标较模糊。
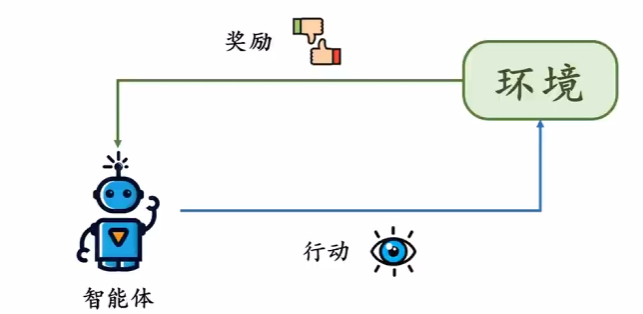
- 强化学习(Reinforcement Learning, RL)
核心特点:通过与环境交互学习策略,以最大化累积奖励。
目标:训练智能体(Agent)在动态环境中做出最优决策。
通过正反馈和负反馈调整学习策略
- 强化学习更关注长期累积奖励,而非单步的“满足目标”,追求的是全局最优解。
- 强化学习通常假设环境满足马尔可夫性(当前状态包含所有历史信息),这是理论建模的基础。
- 目标通常被量化为奖励函数(Reward Function),而不仅仅是简单的“满足/不满足”。
- 强化学习中不一定显式定义惩罚,惩罚可以通过“负奖励”(如奖励值为负数)实现。
- 某些场景中,环境可能不直接给出惩罚,而是通过“未获得奖励”间接反馈
- 策略调整依赖于价值函数(Value Function)或策略梯度(Policy Gradient)
核心要素:
状态(State):环境的当前情况。
动作(Action):智能体的行为。
奖励(Reward):环境对动作的反馈。
策略(Policy):定义智能体在特定状态下选择动作的规则,可以是确定性的或概率性的
价值函数(Value Function):评估状态或动作的长期价值
迷宫导航:
目标:找到出口。
奖励:到达出口+10,每一步消耗-1(鼓励快速找到出口)。
策略调整:智能体通过Q-learning更新动作价值,最终学会最短路径。AlphaGo:
目标:赢棋。
奖励:胜利+1,失败-1,无中间奖励。
策略调整:通过自我对弈(Self-play)和蒙特卡洛树搜索(MCTS)优化策略。机器人行走:
目标:稳定移动。
奖励:前进速度+0.1,摔倒-10。
策略调整:使用PPO算法优化动作策略
强化学习的本质是在动态环境中通过试错和反馈学习最优决策策略